7 Pubblicazione e strumenti di ricerca
L’art. 9 del Decreto contiene le previsioni normative relative alle modalità per facilitare la ricerca di dati e documenti resi disponibili per il riutilizzo, con l’indicazione dei due strumenti nazionali a tale scopo deputati, ovvero il portale nazionale dei dati aperti dati.gov.it e il Repertorio Nazionale dei Dati Territoriali.
Quanto alla pubblicazione dei dati, la Direttiva e il Decreto hanno individuato nelle API (Application Programming Interface) lo strumento per rendere disponibili i dati dinamici e le serie di dati di elevato valore (v. art. 6, comma 5 e art. 12-bis del Decreto).
Il presente capitolo, oltre alle indicazioni relative alle disposizioni di cui sopra, contiene anche ulteriori indicazioni non vincolanti - in quanto non derivanti da specifiche disposizioni normative - per la pubblicazione dei dati, già presenti nelle Linee Guida per la valorizzazione del patrimonio informativo pubblico.
7.1 Pubblicazione dei dati
7.1.1 API
Per i dati dinamici e le serie di dati di elevato valore, il Decreto prevede che i dati debbano essere resi disponibili attraverso un’interfaccia per programmi applicativi (API), che, come da definizione, è un insieme di funzioni, procedure, definizioni e protocolli per la comunicazione da macchina a macchina e lo scambio ininterrotto di dati. Questo non impedisce, ovviamente, che i titolari dei dati possano continuare a rendere disponibili i dati anche in modalità diverse. Del resto, lo stesso art. 50-ter, comma 7 del CAD prevede che le PA possano “continuare a utilizzare anche i sistemi di interoperabilità già previsti dalla legislazione vigente”.
La Direttiva evidenzia che per la creazione e l’impiego di API sia necessario basarsi su alcuni principi: disponibilità, stabilità, manutenzione per tutto il ciclo di vita, uniformità di utilizzo e delle norme, facilità d’uso e sicurezza.
In tema di API, con la Determinazione di AgID n. 547/2021 sono state adottate le “Linee Guida sull’interoperabilità tecnica delle Pubbliche Amministrazioni” [LG-INT] e le “Linee Guida Tecnologie e standard per la sicurezza dell’interoperabilità tramite API dei sistemi informatici” [LG-SIC], che definiscono le modalità con cui le Pubbliche Amministrazioni implementano le proprie API, quale elemento
tecnologico di base del Modello di Interoperabilità (ModI), e individuano le soluzioni tecniche idonee a garantire l’autenticazione dei soggetti coinvolti e la protezione, l’integrità e la riservatezza dei dati scambiati nelle interazioni tra sistemi informatici della pubblica amministrazione e di questi con i sistemi informatici di soggetti privati per il tramite di API.
Le API che il Decreto indica di utilizzare per rendere disponibili dati dinamici e serie di dati di elevato valore DEVONO essere sviluppate e pubblicate in conformità con le Linee Guida citate innanzi.
Dette Linee Guida individuano il Catalogo delle API quale componente, unica e centralizzata, che assicuri alle parti coinvolte nel rapporto di erogazione e fruizione la consapevolezza sulle API disponibili, e per esse, i livelli di servizio dichiarati. Tale Catalogo, in applicazione dell’art. 50 ter del CAD, è reso disponibile attraverso la Piattaforma Digitale Nazionale Dati (PDND) a cui si applicano le indicazioni delle “Linee Guida sull’infrastruttura tecnologica della Piattaforma Digitale Nazionale Dati per l’interoperabilità dei sistemi informativi e delle basi di dati” adottate con la Determinazione di AgID n. 627/2021 [LG-PDND].
La coerenza con le Linee Guida suddette garantisce anche l’adempimento di quanto previsto nel Regolamento (UE) [REG-HVD] relativo ai dati di elevato valore (v. par. 4.3), in particolare con la previsione di cui all’art. 3(2) circa le condizioni di utilizzo delle API e i criteri di qualità del servizio.
Il paragrafo del Regolamento citato dispone, infatti, che debbano essere stabiliti e pubblicati i termini di utilizzo delle API e i criteri di qualità dei servizi in relazione a prestazione, capacità e disponibilità. Tale disposizione può essere estesa anche oltre l’ambito di applicazione del suddetto Regolamento, applicandola in modo generalizzato in modo che i titolari dei dati assumano impegni precisi e non ci si affidi al criterio del best-effort. Nel caso dei servizi di rete INSPIRE, i criteri di qualità sono definiti con il Regolamento (CE) n. 976/2009 e s.m.i. In generale, occorre fare riferimento ai requisiti e alle indicazioni sulla qualità dei servizi definiti nelle Linee Guida sull’interoperabilità tecnica delle Pubbliche Amministrazioni.
Considerato che, come evidenziato dalla Direttiva, è, in generale, vantaggioso riutilizzare e condividere i dati tramite un impiego adeguato di API, perché possono aiutare gli sviluppatori e le start-up a creare nuovi servizi e prodotti e rappresentano, inoltre, un elemento fondamentale della strutturazione di ecosistemi di valore attorno a un patrimonio di dati spesso inutilizzato, è fortemente raccomandato l’utilizzo di API per rendere disponibili per il riutilizzo anche quelle tipologie di dati per le quali il Decreto non prevede tale disposizione.
In caso di serie storiche di dati, la pubblicazione dovrebbe riguardare non solo i dati più recenti o attuali, ma tutta la successione in modo da non disperdere un patrimonio informativo importante utile, per esempio, per analisi sull’evoluzione dei vari fenomeni di interesse.
Nel caso di dati territoriali, viste le regole tecniche di cui alle Linee Guida INSPIRE per l’implementazione dei servizi di rete di cui all’art. 7, comma 1 del D. Lgs.n. 32/2010 [D-LGS-32-2010], detti servizi di rete possono essere considerati come API in considerazione del fatto che nell’ambito delle Linee Guida sull’interoperabilità tecnica delle PA, accettando la nomenclatura in uso a livello europeo e più in generale nel contesto internazionale, si utilizza il termine generico API per indicare indifferentemente le Web API, i web service e le API REST.
Nel caso dell’applicazione del REQUISITO 28, fermo restando, comunque, quanto previsto dal già citato art. 50-ter, comma 7 del CAD, detti servizi potrebbero essere documentati anche nel catalogo API disponibile nella PDND.
7.1.1.1 Sicurezza e disponibilità dei dati
L’art. 51, comma 1 del CAD demanda a specifiche Linee guida l’individuazione delle soluzioni tecniche idonee a garantire la protezione, la disponibilità, l’accessibilità, l’integrità e la riservatezza dei dati e la continuità operativa dei sistemi e delle infrastrutture.
Tali Linee Guida sono state definite nell’ambito del modello di interoperabilità delle pubbliche amministrazioni e corrispondono alle già citate Linee Guida “Tecnologie e standard per la sicurezza dell’interoperabilità tramite API dei sistemi informatici” [LG-SIC], che definiscono le tecnologie e le loro modalità di utilizzo al fine di garantire la sicurezza delle transazioni digitali realizzate tra e verso le pubbliche amministrazioni che utilizzano le API tramite rete di collegamento informatica.
L’implementazione di API coerenti con il REQUISITO 27, pertanto, assicura il rispetto degli adempimenti e la conformità al citato art. 51 del CAD.
Nell’ambito della Strategia Cloud Italia (v. box “Risorse utili”), a cui si rimanda, inoltre, al fine di regolamentare l’offerta di servizi cloud disponibili sul mercato per mitigare i rischi sistemici di sicurezza e affidabilità, è stata definita una classificazione dei dati e dei servizi allo scopo di definire un processo di classificazione dei dati, in base al danno che una loro compromissione potrebbe provocare al sistema Paese (strategici, critici e ordinari). Il risultato della classificazione, si legge nella strategia, consente di uniformare e guidare il processo di migrazione al Cloud della PA. Le classi individuate sono:
- Strategico: dati e servizi la cui compromissione può avere un impatto sulla sicurezza nazionale;
- Critico: dati e servizi la cui compromissione potrebbe determinare un pregiudizio al mantenimento di funzioni rilevanti per la società, la salute, la sicurezza e il benessere economico e sociale del Paese;
- Ordinario: dati e servizi la cui compromissione non provochi l’interruzione di servizi dello Stato o, comunque, un pregiudizio per il benessere economico e sociale del Paese.
7.1.2 Elementi architetturali
I principali livelli architetturali che compongono una soluzione per la pubblicazione e l’interrogazione di dati aperti possono essere istanziati in diverso modo a seconda delle capacità economiche e tecniche delle amministrazioni, nonché della qualità del servizio che si vuole offrire agli utenti. Si distinguono due livelli: livello di front-end e livello infrastrutturale. Il livello di front- end consiste di una parte di presentazione che può essere sia un sito Web, sia una sezione in un sito esistente. In questa parte rientrano tutti quegli strumenti che consentono di dare massima visibilità ai dati disponibili e di interagire in maniera “user-friendly” con gli utenti stessi, per esempio per capire quali dati siano di loro interesse, quali nuovi dati siano richiesti, quali suggerimenti vogliano dare per migliorare anche la qualità dei dati. Il livello di presentazione si completa con l’interfaccia di accesso via web per interrogazioni puntuali sui dati e sui metadati. L’interfaccia ha come obiettivo quello di aumentare l’interazione machine-to-machine attraverso il dispiegamento di una piattaforma di esposizione dati basata su API di servizio (o Open Data Service). Nel caso di dati dei livelli 4 e 5 del modello per i dati di cui all’Allegato A, l’interfaccia di accesso via web è rappresentata dallo SPARQL endpoint.
In generale, SI RACCOMANDA di:
- assegnare ai dataset nomi autoesplicativi per comprenderne il principale contenuto;
- fornire, ove possibile, descrizioni testuali dei dataset;
- mettere in evidenza la licenza in uso in forma “human and machine-readable”;
- fornire, ove possibile, strumenti di visualizzazione e navigazione, anche georiferita, dei dati, che possano facilitare la lettura degli stessi;
- fornire, ove possibile, statistiche di uso, accesso e produzione;
- fornire notifiche di cambiamenti nel sito web, di aggiornamenti ai dataset (per es., RSS feed);
- fornire strumenti per rendere le interrogazioni più agevoli, anche per utenti non del tutto esperti. Nel caso dei dati dei livelli 4 e 5 non si può pubblicare solo dataset RDF ma è bene mettere in evidenza la presenza dello SPARQL endpoint (cioè, un servizio Web che accetta interrogazioni SPARQL, le risolve e restituisce i risultati in output), pubblicando il link di accesso, fornendo altresì un ampio insieme di “query” di esempio che possono essere eseguite producendo risultati disponibili in diversi formati di più comune utilizzo soprattutto nell’ambito delle comunità open data (per es., CSV, JSON, XML).
Nei casi di amministrazioni di minori dimensioni o amministrazioni che non siano nelle condizioni di poter fornire un servizio con le caratteristiche sopra elencate, si consiglia di implementare azioni di sussidiarietà verticale (ad esempio, i comuni di medio-piccole dimensioni possono riferirsi alla Regione di appartenenza) o di unirsi in iniziative comuni (v. paragrafo 5.1.1.1).
Il livello infrastrutturale è rappresentato dall’infrastruttura che ospita i dati e i metadati. Nel caso di dati aperti, tenuto conto della loro natura intrinseca, ovvero di dati tipicamente non riferibili a singole persone e per i quali solitamente non si richiede il soddisfacimento di specifici requisiti di protezione dei dati personali, tecnologie basate sul paradigma del cloud computing pubblico possono essere facilmente impiegabili al fine di ospitare le infrastrutture per la pubblicazione di dati aperti.
In tema di cloud, la Strategia Cloud Italia (v. box “Risorse utili”), già citata innanzi, definita dal Dipartimento per la trasformazione digitale della Presidenza del Consiglio dei Ministri e dall’Agenzia per la cybersicurezza nazionale (ACN), contiene gli indirizzi strategici per il percorso di migrazione verso il cloud di dati e servizi digitali della Pubblica Amministrazione. Per l’attuazione della strategia, AgID ha adottato, con la Determinazione n. 628/2021, il Regolamento che definisce i requisiti minimi per le infrastrutture digitali e le caratteristiche e le modalità di qualificazione e migrazione dei servizi cloud.
7.1.3 Identificatori univoci e persistenti
Nei requisiti per i dati della ricerca volti a rendere tali dati conformi ai principi FAIR si è fatto riferimento più volte a identificatori univoci e persistenti. Tali identificatori (che è buona prassi applicare a tutti i dati e non solo a quelli della ricerca) sono generalmente rappresentati dagli URI (Uniform Resource Identifier), una sequenza di caratteri che identifica una risorsa astratta o fisica. Essi sono utilizzati nei linked data (v. par. 5.1.4) per risolvere il problema dell’identità.
Gli URI DEVONO essere persistenti e dereferenziabili. Una politica per garantire URI persistenti e fornire aspetti di naming è proposta in uno studio dalla Commissione Europea (v. box “Risorse utili” in calce). Facendo riferimento a tale documento, per la creazione di URI persistenti sono da evitare quelli che contengano:
- nome del progetto/ufficio/unità amministrativa che detiene la risorsa per evitare problemi derivanti dalla fine del progetto stesso o fusioni o chiusure di uffici nell’organizzazione;
- numeri di versione;
- identificatori esistenti che in passato siano stati utilizzati per identificare risorse differenti;
- riferimenti generati in modo automatico e incrementale a meno che non vi sia la garanzia che il processo non venga mai più ripetuto o, se ripetuto, generi sicuramente gli stessi identificatori per gli stessi dati di input;
- stringhe rappresentanti “query” a database;
- estensione del file.
Sono, invece, da ritenersi buone pratiche le seguenti:
- strutturare l’URI come segue:
http://{dominio}/{tipo}/{concetto}/{riferimento}
- includere nell’ URI i seguenti elementi:
- dominio: il dominio Web su cui reperire la risorsa
- tipo: l’elemento che specifica il tipo di risorsa. Dovrebbe poter assumere un numero limitato di valori come “doc” se la risorsa identificata è un documento descrittivo, “set” se la risorsa è un dataset, “id” o “item” se la risorsa è un oggetto del mondo reale
- concetto: il tipo di un oggetto del mondo reale
- riferimento: lo specifico elemento, termine o concetto che rappresenta la risorsa
- costruire URI per più formati al fine di identificare al meglio la risorsa
- collegare tra loro le rappresentazioni multiple della stessa risorsa
- implementare il codice di risposta 303 per gli oggetti del mondo reale e risorse in generale (si veda di seguito “content negotiation” e “dereferenziazione” degli URI)
- utilizzare servizi dedicati.
Nella gestione degli URI è opportuno utilizzare il meccanismo cosiddetto di “content negotiation” che consente di rendere disponibile, allo stesso URI, diverse rappresentazioni di una risorsa in caso di molteplici rappresentazioni possibili (per es. URI che rappresentano sia entità del web semantico sia risorse web). Analogamente, è una buona prassi utilizzare sempre URI “deferenziabili”, come già indicato prima, cioè URI che restituiscono una rappresentazione web (ad es. una pagina web informativa) di una risorsa.
7.2 Strumenti per la ricerca
Il Decreto individua come strumenti per la ricerca dei dati il catalogo nazionale dei dati aperti e, per i dati territoriali, il Repertorio Nazionale dei Dati Territoriali (RNDT) di cui all’art. 59 del CAD, entrambi gestiti da AgID.
Ai sensi dell’articolo 9 del Decreto, il portale nazionale dei dati aperti (dati.gov.it) è l’unico riferimento per la documentazione e la ricerca di tutti i dati aperti della pubblica amministrazione. Esso, in quanto punto di accesso nazionale per i metadati dei dati aperti, è l’unico ad abilitare il colloquio con l’analogo portale ufficiale dei dati europei data.europa.eu. Il portale nazionale include i metadati, conformi al profilo DCAT-AP_IT, che descrivono i dati aperti delle amministrazioni secondo quanto indicato al par. 4.6.
I dati, il cui riferimento è pubblicato sul portale nazionale, rimangono presso il titolare del dato che conserva la responsabilità della loro correttezza, tenuta, gestione, aggiornamento e divulgazione a livello nazionale.
L’integrazione dei due cataloghi avviene attraverso la specifica GeoDCAT-AP che fornisce una sintassi RDF per i metadati INSPIRE e ISO 19115 (profilo core) e la sua estensione italiana che è stata definita con la Guida nazionale per l’implementazione della specifica GeoDCAT-AP (v. box “Risorse utili”).
Nella citata Guida sono definite, tra l’altro, le due regole principali così formulate:
- I dati territoriali, anche quando siano resi disponibili secondo il paradigma open data, DEVONO essere documentati ESCLUSIVAMENTE nel RNDT secondo le regole nazionali sui metadati dei dati territoriali e le relative guide operative;
- Il RNDT garantirà l’accesso ai dati territoriali “di tipo aperto” anche nel catalogo nazionale dei dati aperti (dati.gov.it), secondo lo standard DCAT-AP_IT, attraverso GeoDCAT-AP e sulla base delle corrispondenze definite nel documento.
Sulla base di queste regole e delle corrispondenze definite tra i metadati dei due standard di riferimento, i dati territoriali aperti documentati nel RNDT sono resi accessibili attraverso le funzionalità tipiche del catalogo nazionale dei dati aperti, dati.gov.it, senza nessun ulteriore adempimento da parte dei titolari di dati.
Come indicato nelle Linee Guida RNDT [LG-RNDT], il Repertorio, in quanto punto di accesso nazionale per i metadati dei dati territoriali, provvede a rendere disponibili i metadati anche al geoportale INSPIRE secondo le modalità individuate per l’applicazione di INSPIRE-DIR, anche ai fini delle operazioni di monitoraggio di cui alla Decisione di esecuzione (UE) 2019/1372 della Commissione Europea1.
Nella figura che segue è rappresentato lo schema di coordinamento e integrazione tra i due cataloghi nazionali e la loro interazione con i portali europei.
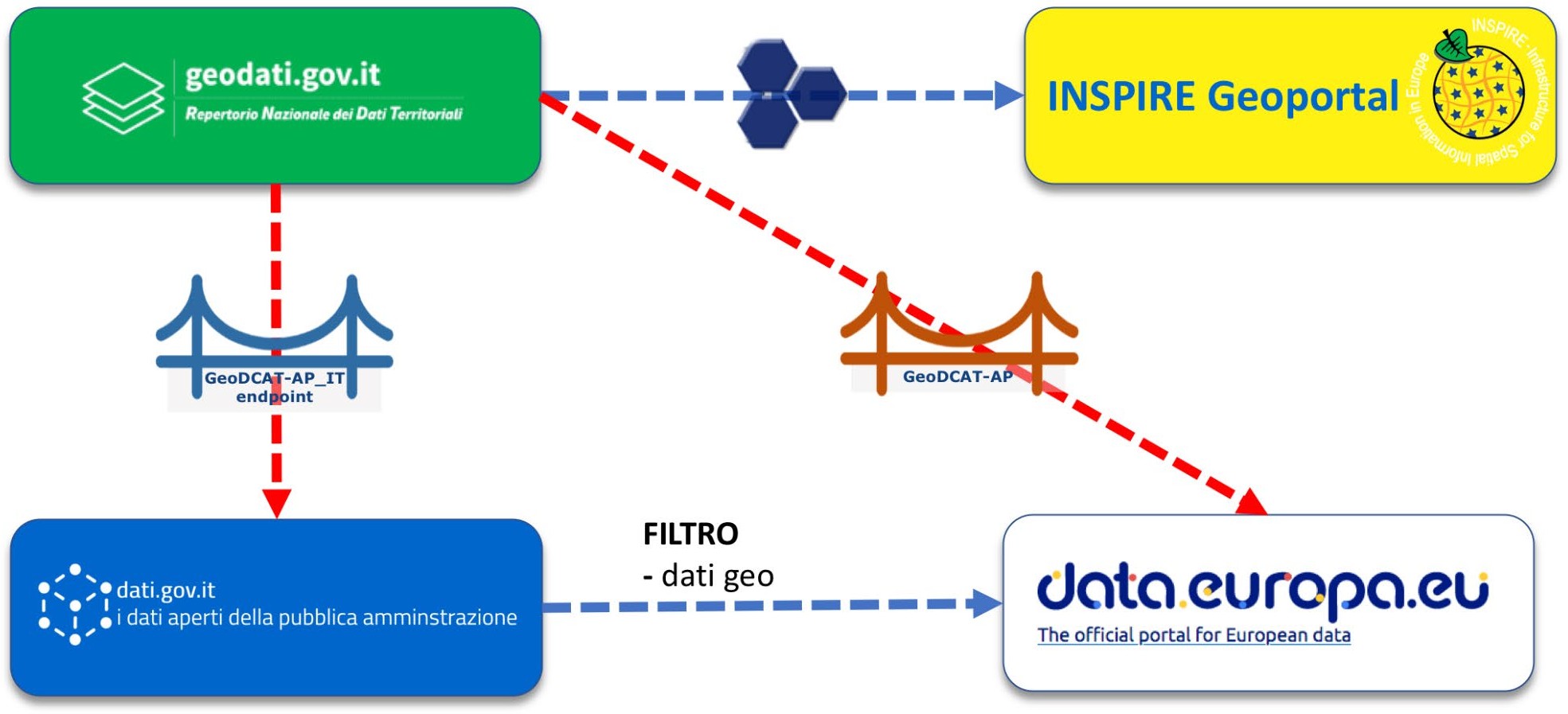
Come indicato nella guida nazionale su GeoDCAT-AP, quanto sopra è riferito alla integrazione dei cataloghi nazionali RNDT e dati.gov.it e all’allineamento delle informazioni in essi contenute; ferma restando la possibilità di un diverso orientamento, SI RACCOMANDA alle amministrazioni di adottare l’approccio nazionale anche nella gestione dei cataloghi “locali”.
Analogamente ai dati territoriali, anche per i dati statistici è stata definita un’estensione della specifica DCAT-AP, denominata StatDCAT-AP2 (v. box “Risorse utili”), allo scopo di garantire la disponibilità dei dati statistici, utilizzando gli standard specifici, come SDMX, anche nei portali generalisti dei dati aperti.
7.2.1 Elenchi delle categorie e modalità di ricerca
Il Decreto dispone che i soggetti destinatari delle presenti Linee Guida debbano individuare le modalità per facilitare la ricerca, anche interlinguistica, dei documenti disponibili per il riutilizzo, insieme ai rispettivi metadati, ove possibile accessibili on-line e in formati leggibili meccanicamente. Tale disposizione è attuata attraverso il rispetto del REQUISITO 20 e REQUISITO 21 definiti innanzi.
Il Decreto prevede, inoltre, quanto indicato nel seguente Requisito 31.
Per adempiere a tale disposizione, considerato che in base ai Requisiti 20 e 21 i dati DEVONO essere documentati nel portale nazionale dei dati aperti dati.gov.it, si può pubblicare nel proprio sito istituzionale, eventualmente in una sezione dedicata agli open data, anche al fine di evitare eventuali duplicazioni, un collegamento ipertestuale (anche sfruttando le API disponibili nel portale nazionale), per ciascuna categoria tematica (facendo riferimento ai temi DCAT-AP), ai propri dataset pubblicati nel portale nazionale. Un esempio di URL da inserire nel proprio sito istituzionale è il seguente:
https://dati.gov.it/view-dataset?holder_name=%22Provincia%20Autonoma%20di%20Trento%22&groups=ambiente
dove l’amministrazione titolare è la Provincia Autonoma di Trento e la categoria è “ambiente”.
Le categorie tematiche da considerare sono quelle corrispondenti ai temi definiti nell’ambito della specifica DCAT-AP3 che si riportano di seguito:
- Agricoltura, pesca, silvicoltura e prodotti alimentari;
- Ambiente;
- Economia e finanze;
- Energia;
- Giustizia, sistema giuridico e sicurezza pubblica;
- Governo e settore pubblico;
- Istruzione, cultura e sport;
- Popolazione e società;
- Regioni e città;
- Salute;
- Scienza e tecnologia;
- Tematiche internazionali;
- Trasporti.
Tali temi, in quanto definiti nel profilo di metadati DCAT-AP_IT, sono già utilizzati come classificazione dei dataset nei portali dei dati aperti, a partire da quello nazionale dati.gov.it.
Nel caso di dati territoriali aperti, come già indicato, questi vanno documentati esclusivamente nel RNDT che li renderà disponibili anche in dati.gov.it, consentendo, quindi, la creazione del collegamento ipertestuale di cui sopra.
Per la pubblicazione dei metadati nel catalogo nazionale, ci si può avvalere dei principi di sussidiarietà verticale, già in precedenza menzionati, o adottare autonomamente una delle possibili soluzioni descritte di seguito.
Per quanto riguarda la sussidiarietà verticale, nell’ambito locale, le Regioni possono assumere il ruolo di aggregatori territoriali. In sostanza, la Regione, ove possibile, si coordina con le varie amministrazioni che operano nell’ambito territoriale della Regione stessa, raccogliendo le informazioni sui dataset disponibili come dati aperti e assicurando una adeguata frequenza di aggiornamento. Le amministrazioni locali delegano così la Regione all’esposizione dei propri metadati e possono evitare di richiedere direttamente la raccolta degli stessi da parte del portale nazionale; quest’ultimo si interfaccia quindi con i soli cataloghi regionali.
Lo stesso modello può applicarsi nei casi di amministrazioni centrali che svolgano un ruolo di “coordinamento” nei riguardi di altre amministrazioni. In questo caso, si richiede che le amministrazioni comunichino tale situazione al portale nazionale durante la fase di richiesta di raccolta.
Per quanto riguarda le possibili soluzioni “autonome”, che possono essere adottate anche qualora il modello di sussidiarietà di cui sopra non potesse essere applicato (per es., per mancanza di un catalogo regionale o difficoltà, anche tecniche, di colloquio tra i diversi livelli amministrativi locali), di seguito si riportano alcune di queste possibili soluzioni per la creazione di piattaforme di pubblicazione dei dati.
Soluzione nativa. Viene creato un portale ad-hoc o creata un’apposita sezione di un portale esistente. In questo caso, la creazione non differisce dalla creazione di un sito web classico.
Estensione soluzione CMS esistente. Molto spesso l’amministrazione gestisce già un sito web, realizzato mediante l’uso di un CMS, che vuole estendere con una sezione dedicata agli Open Data. La criticità in questo caso è data dall’aggiunta di una componente semantica all’interno della configurazione del CMS stesso.
Utilizzo di piattaforme esterne. Viene utilizzata una piattaforma che include funzionalità per la catalogazione, visualizzazione, ricerca e interrogazione dei dati. In alcuni casi queste piattaforme sono disponibili in modalità «as a service».
NdR: queste linee guida sono una versione derivata dal documento ufficiale pubblicato da AgID in formato PDF. Questo sito web non è un documento ufficiale e si prega di fare riferimento al suddetto PDF.
Decisione di esecuzione (UE) 2019/1372 della Commissione del 19 agosto 2019 recante attuazione della direttiva 2007/2/CE del Parlamento europeo e del Consiglio per quanto riguarda il monitoraggio e la comunicazione↩︎
Attualmente l’estensione StatDCAT-AP è allineata alla versione 1.1 di DCAT-AP↩︎
- il relativo vocabolario controllato disponibile al link https://op.europa.eu/en/web/eu-vocabularies/concept-scheme/-/resource?uri=http://publications.europa.eu/resource/authority/data-theme