5 Analisi
Il Decreto non contiene specifiche disposizioni sugli aspetti organizzativi e di qualità dei dati. Si ritiene però, utile, riportare nel seguito alcune indicazioni mirate, alcune delle quali, peraltro, già presenti nelle Linee Guida per la valorizzazione del patrimonio informativo pubblico, sebbene organizzate diversamente e ove necessario integrate e/o riviste, come raccomandazioni su tali aspetti che si ritengono cruciali per un processo di apertura e di riutilizzo efficace e sostenibile.
I requisiti presenti in questo capitolo sono relativi esclusivamente alle richieste di riutilizzo esplicitamente previste dal Decreto (cfr. art. 5), nella nuova formulazione introdotta con il decreto legislativo n. 200/2021 [D-LGS-200-2021].
5.1 Aspetti organizzativi
Il processo di apertura di un dato è frutto di una catena di processi e di una serie di attività di analisi ed elaborazione finalizzate al miglioramento della qualità e dell’accesso al dato stesso.
Nella Figura 5.1 che segue è rappresentato un possibile percorso di preparazione dei dati per garantirne la produzione e la pubblicazione e/o messa a disposizione di qualità, necessariamente elastico per garantirne, parimenti, l’applicabilità alle diverse realtà amministrative del territorio nazionale.
La rappresentazione di tale percorso è un adattamento dell’analogo processo definito nel documento “Data quality guidelines” dell’Ufficio delle Pubblicazioni della Commissione Europea1. Uno schema analogo, sebbene riferito ai linked open data, è definito anche nelle Linee Guida per l’interoperabilità semantica attraverso i Linked Open Data2. A tale proposito, SI RACCOMANDA di seguire le suddette Linee Guida per il processo di produzione di Linked Open Data.
In considerazione del possibile diverso punto di partenza del processo di apertura dei dati, alcune fasi indicate nel percorso suddetto possono non essere prese in considerazione. Se, per esempio, l’obiettivo è quello di produrre un nuovo dato - quindi non ancora esistente - le attività di ricognizione e di analisi possono essere by-passate e le prime fasi da considerare potranno essere quella della modellazione e della definizione di priorità e del percorso di apertura (inserita nella fase di identificazione), che rimane comunque valida. Il percorso, inoltre, potrebbe essere modulato anche in forma ciclica, organizzando eventualmente le attività previste in più interazioni.
L’implementazione del processo deve avvenire in maniera costante: le attività non si esauriscono con la mera pubblicazione dei dati, ma devono prevedere momenti continui di aggiornamento, monitoraggio e coinvolgimento degli utenti finali, fasi non rappresentate nel percorso in oggetto ma ugualmente importanti per graduare il processo di apertura e pubblicazione dei dati sulle effettive esigenze degli utenti.
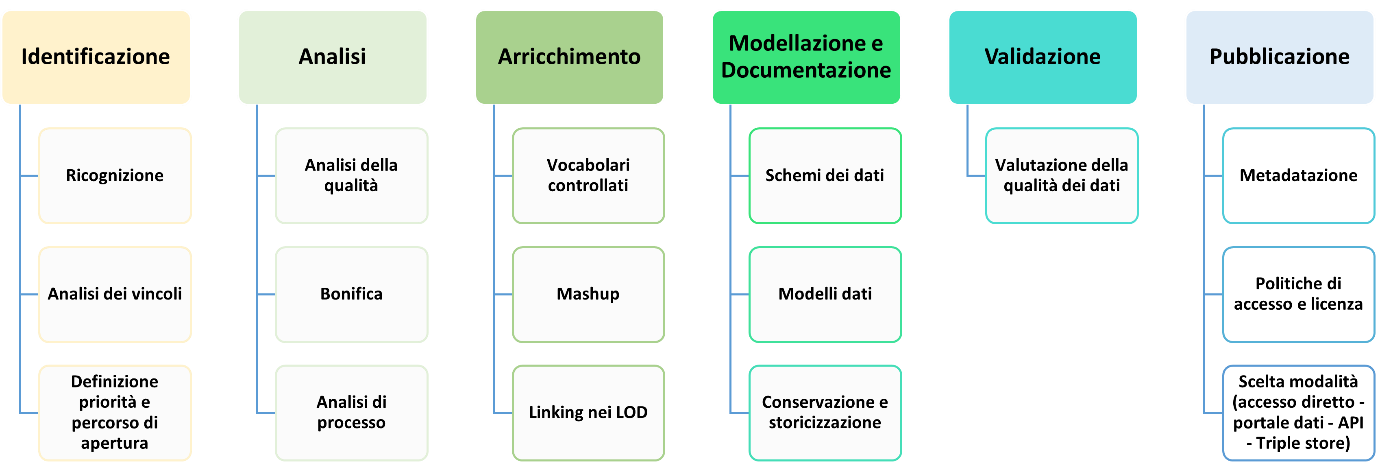
Un altro modello metodologico per la gestione dei dati aperti è rappresentato da Open Data Management Cycle (ODMC), già utilizzato in alcune Pubbliche Amministrazioni, che include un modello dei processi, un modello informativo e un modello organizzativo. Per tutti gli aspetti che sono allineati alle presenti Linee Guida, il modello indicato può rappresentare un utile riferimento per un approccio comune alla gestione del patrimonio informativo. Nel modello indicato, inoltre, sono presenti indicazioni anche per le fasi non considerate nel processo rappresentato nella Figura 5.1.
Ai fini di valutare l’efficacia del processo di apertura, è anche utile misurare l’impatto dell’utilizzo dei dati aperti. Non esiste una definizione di “impatto dei dati aperti” nella legislazione o nella documentazione tecnica nazionale. Esso può essere inteso come l’insieme degli effetti e dei benefici ottenuti direttamente o indirettamente dall’utilizzo e/o il riutilizzo dei dati aperti in specifiche politiche, aree o domini. In linea con il rapporto sulla maturità dei dati aperti in Europa pubblicato annualmente3, i domini rispetto ai quali misurare l’impatto possono essere: società, governo, economia e ambiente.
Di seguito alcune indicazioni per ciascun tipo di impatto come presenti nel rapporto di cui sopra:
- Impatto sociale - Valuta la misura in cui i dati aperti hanno un impatto sulle sfide sociali, come l’inclusione dei gruppi emarginati nella società, l’aumento di sensibilizzazione riguardo all’edilizia abitativa nelle aree urbane, e le questioni legate alla salute e al benessere;
- Impatto politico - Si concentra sui benefici che i dati aperti hanno in tre ambiti: miglioramento dell’efficienza del governo, miglioramento dell’efficacia del governo e aumento della trasparenza e della responsabilità;
- Impatto economico - Considera aspetti quali l’impatto macro e micro- economico e i benefici economici per le amministrazioni pubbliche;
- Impatto ambientale - Considera aspetti quali la sensibilizzazione sulla qualità dell’acqua e dell’aria, i livelli di rumore nelle città, i sistemi di gestione dei rifiuti, i sistemi di trasporto rispettosi dell’ambiente.
5.1.1 Ruoli e responsabilità
Per attuare il processo indicato innanzi è necessario definire innanzitutto una chiara data governance interna con l’individuazione di ruoli e relative responsabilità e integrare le sue fasi sia verticalmente, rispetto ai processi interni già consolidati, che orizzontalmente rispetto alle necessità delle diverse amministrazioni.
L’autonomia organizzativa delle attività di ciascuna Amministrazione non consente di definire un modello unico per la gestione del processo di apertura dei dati e di implementazione delle indicazioni definite nelle presenti Linee Guida, vista anche la clausola di invarianza finanziaria di cui all’art. 13 del Decreto.
Ogni Amministrazione e, all’interno di essa, ogni unità organizzativa POSSONO individuare e definire un proprio modello procedurale che individui ruoli e responsabilità dei soggetti coinvolti sulla base delle disponibilità finanziarie, umane e strumentali e nel rispetto della normativa nazionale e unionale in materia di protezione dei dati personali, laddove questi siano coinvolti nelle attività di trattamento.
Per le autonomie locali occorre tenere conto, in particolare, di quanto disposto dall’art. 12 del decreto legislativo 18 agosto 2000, n. 267 e dall’art. 1, comma 85, lettera d) della legge 7 aprile 2014, n. 56, relativamente alla gestione dei sistemi informativi e statistici locali e alla funzione fondamentale di Province e Città Metropolitane in materia di raccolta ed elaborazione dati.
Un ruolo essenziale per l’organizzazione di uffici e risorse per il processo di apertura e di riutilizzo dei dati può essere svolto dall’ufficio del Responsabile per la transizione digitale (RTD) istituito con l’art. 17 del CAD, che ha la responsabilità della transizione alla modalità operativa digitale e che risponde direttamente all’organo di vertice politico o, in assenza di questo, a quello amministrativo dell’ente.
La Circolare n. 3 del 1° ottobre 2018 del Ministro per la pubblica amministrazione (v. box “Risorse utili”), al fine di garantire la piena operatività dell’Ufficio del RTD, raccomanda di prevedere, nell’atto di conferimento dell’incarico o di nomina, oltre che i compiti espressamente previsti dalle norme vigenti in materia, anche il potere di costituire gruppi tematici per singole attività e/o adempimenti come può essere il processo di apertura e pubblicazione dei dati.
Nel caso in cui tale potere non sia assegnato al RTD, la costituzione del gruppo “tematico” può essere direttamente decisa dal vertice politico o quello amministrativo.
In ogni caso, il RTD DEVE essere comunque coinvolto, stante il suo ruolo di riferimento del vertice politico e/o amministrativo e di figura trasversale a tutta l’organizzazione con potere di agire su tutte le articolazioni amministrative dell’ente, da una parte, e di punto di contatto con l’Agenzia per l’Italia Digitale e la Presidenza del Consiglio dei Ministri, dall’altra, per le questioni connesse alla trasformazione digitale delle pubbliche amministrazioni, come ribadito anche nella citata Circolare n. 3/2018.
Considerata, inoltre, la disciplina relativa ai dati territoriali, definita da uno specifico framework di interoperabilità a livello europeo (v. par. 4.5), è importante garantire un opportuno raccordo anche con le figure coinvolte nella politica e nella gestione di tali dati, a partire dai rappresentanti dell’amministrazione nella Consulta Nazionale per l’Informazione Territoriale ed Ambientale (CNITA), di cui all’art. 11 del decreto legislativo n. 32/2010 [D-LGS-32-2010], se presenti o, in generale, dai referenti delle infrastrutture di dati territoriali.
Nel processo di apertura e riutilizzo dei dati, ove siano coinvolti dati personali, il Responsabile per la protezione dei dati DEVE essere necessariamente coinvolto, ai sensi dell’art. 38, par. 1 del [GDPR].
Visto quanto premesso, nelle presenti Linee Guida si considera il gruppo di lavoro per i dati aperti come possibile struttura per il governo del processo di apertura dei dati, rimandando all’autonomia organizzativa di ciascun ente la previsione di eventuali altre strutture e figure, oltre all’individuazione dei compiti da assegnare ad essi.
All’interno del gruppo di lavoro, o comunque nell’ambito dell’organizzazione dell’ente, è bene prevedere un responsabile per l’apertura dei dati e il coinvolgimento dei responsabili e/o dei referenti tematici che gestiscono e trattano dati nell’ambito delle singole unità organizzative, oltre alle figure che possano fornire il necessario supporto per l’analisi della qualità dei dati, per la protezione dei dati personali eventualmente presenti, per la definizione delle interfacce di accesso ai dati, per la promozione di applicazioni sviluppate a partire dai dati pubblicati, fornendo anche, laddove necessario, esempi di servizi dimostrativi attraverso cui incentivare il riutilizzo. Alcuni membri del team (per es., esperti di tecnologie web, esperti GIS, esperti di tecnologie e strumenti per i Linked Data) possono occuparsi della gestione del processo di apertura del dato dal punto di vista IT.
È importante garantire il raccordo e la consultazione con le altre figure coinvolte nel processo di digitalizzazione della pubblica amministrazione, ovvero responsabile per la conservazione documentale, responsabile per la prevenzione della corruzione e la trasparenza,
responsabile della protezione dei dati, responsabile dei sistemi informativi (se non coincide con il RTD), responsabile per la sicurezza.
L’azione di raccordo e consultazione di cui sopra può essere espletata dal RTD a cui, sulla base della Circolare n. 3/2018 citata innanzi, può essere deputata, nell’atto di nomina, l’adozione dei più opportuni strumenti per garantire tale azione.
5.1.1.1 Coordinamento tra livello nazionale, regionale e locale
Diverse pubbliche amministrazioni centrali, al fine di adempiere a specifici obblighi normativi a loro assegnati o per dar seguito a impegni presi in iniziative internazionali, hanno necessità di raccogliere dati provenienti dal livello di governo regionale e locale. Viceversa, le amministrazioni centrali e regionali possono detenere dati che sono anche di interesse locale.
In queste situazioni, SI RACCOMANDA alle amministrazioni di coordinarsi tra loro prima di intraprendere iniziative singole isolate. In particolare, le amministrazioni centrali possono assumere un ruolo di coordinamento e di promozione dell’apertura dei dati, definendo anche schemi comuni secondo quanto indicato al par. 5.1.5. Tale ruolo può essere assunto, in alcuni casi, anche dagli altri Enti sovraordinati (Regioni o Province/Città Metropolitane).
SI RACCOMANDA, quindi, di mantenere il colloquio, mediante scambio di dati, tra il livello centrale, regionale e locale attraverso l’uso dei dati aperti stessi, ove presenti, automatizzando quanto più possibile il processo di acquisizione.
5.1.2 Individuazione e selezione
Il processo di apertura dei dati non può che partire da una ricognizione dei dati detenuti e trattati dall’ente e dalla successiva identificazione e selezione di quelli che possono essere resi disponibili per il riutilizzo.
L’apertura può riguardare:
- dati nativi, cioè dati generati dalle amministrazioni nell’adempimento delle proprie funzioni istituzionali;
- dati mashup, cioè dati provenienti da diverse fonti e soggetti a operazioni di integrazione.
In entrambi i casi, l’apertura può essere sollecitata da soggetti esterni interessati attraverso specifiche richieste (v. par. 5.2).
In questa fase si può fare riferimento ad alcune disposizioni che, in taluni casi, prevedono di rendere disponibili i dati a fini di riutilizzo. In particolare, tra gli altri:
- sulla base della disposizione di cui all’art. 7 del [D-LGS-33-2013], “i documenti, le informazioni e i dati oggetto di pubblicazione obbligatoria ai sensi della normativa vigente, resi disponibili anche a seguito dell’accesso civico di cui all’articolo 5” del medesimo decreto, fermi restando i limiti e le cautele previsti per i dati personali (v. par. 4.1);
- ai sensi dell’art. 50-quater del [CAD], relativo ai dati generati nella fornitura di servizi in concessione, tutti i dati acquisiti e generati nella fornitura del servizio agli utenti e relativi anche all’utilizzo del servizio medesimo da parte degli utenti, esclusivamente per fini statistici e di ricerca e per lo svolgimento dei compiti istituzionali delle pubbliche amministrazioni.
Per i nuovi dati, che rientrino nell’ambito di applicazione del Decreto, il processo di produzione e apertura DEVE essere guidato dal principio dell’apertura fin dalla progettazione e per impostazione predefinita, come, tra l’altro, disposto dall’art. 6, comma 4 del Decreto. A tale proposito, nel par. 6.1.2 sono definite una serie di raccomandazioni per applicare il principio dell’“open data by design”.
Al riguardo, occorre in ogni caso ricordare con particolare riferimento ai dati personali, che il legislatore europeo nella Direttiva ha evidenziato che “il riutilizzo dei dati personali è ammissibile soltanto se è rispettato il principio della limitazione della finalità di cui all’articolo 5, paragrafo 1, lettera b) e l’articolo 6 del regolamento (UE) 2016/679” (Considerando n. 52), come anche esplicitato al par. 4.1. Pertanto, come evidenziato anche dal Garante per la protezione dei dati personali, la pubblicazione di informazioni personali online per finalità di trasparenza o di pubblicità dell’azione amministrativa non significa che le stesse costituiscano “dati aperti” né che gli stessi siano, di conseguenza, liberamente riutilizzabili da chiunque e per qualsiasi scopo, bensì impone al soggetto chiamato a dare attuazione agli obblighi di pubblicazione sul proprio sito web istituzionale di determinare – qualora intenda rendere i dati riutilizzabili – se, per quali finalità e secondo quali limiti e condizioni eventuali utilizzi ulteriori dei dati personali resi pubblici possano ritenersi leciti alla luce del “principio di finalità” e degli altri principi di matrice europea in materia di protezione dei dati personali di cui all’art. 5 del [GDPR] (cfr. Linee guida del Garante in materia di trasparenza [LG-GPDP]).
Quanto al principio di finalità, si ricorda che la normativa europea sulla protezione dei dati personali prevede che tali dati debbano essere raccolti per finalità determinate, esplicite e legittime e che possano successivamente essere trattati solo “in modo che non sia incompatibile con tali finalità” (art. 5, par. 1, lett. b del [GDPR]). Tale requisito è confermato anche dall’ art. 6 del [GDPR] laddove è prescritto che il trattamento di dati personali per una finalità diversa da quella per la quale i dati personali sono stati raccolti deve essere”compatibile” con la finalità per la quale i dati personali sono stati inizialmente raccolti.
Al fine di verificare la compatibilità della finalità del riutilizzo dei dati personali con quella per la quale i dati personali sono stati inizialmente raccolti è possibile far riferimento ai criteri contenuti nel Regolamento europeo (art. 6, par. 4 del [GDPR]), che prevede come il titolare del trattamento debba tenere conto, fra l’altro:
- di ogni nesso tra le finalità per cui i dati personali sono stati raccolti e le finalità dell’ulteriore trattamento previsto;
- del contesto in cui i dati personali sono stati raccolti, in particolare relativamente alla relazione tra l’interessato e il titolare del trattamento;
- della natura dei dati personali, specialmente se siano trattate categorie particolari di dati personali ai sensi dell’articolo 9, oppure se siano trattati dati relativi a condanne penali e a reati ai sensi dell’articolo 10;
- delle possibili conseguenze dell’ulteriore trattamento previsto per gli interessati;
- dell’esistenza di garanzie adeguate, che possono comprendere la cifratura o la pseudonimizzazione”.
Per meglio individuare per quali scopi ulteriori, compatibili con quelli originari, i dati personali pubblicamente disponibili online possono essere utilizzati (o debbano altrimenti essere anonimizzati), si vedano gli elementi condivisi in ambito europeo ed elaborati dal Gruppo Art. 29 nel Parere n. 03/2013 sul principio di limitazione della finalità (v. box “Risorse utili”).
Ricognizione - Per i dati nativi, vanno, quindi, individuati, nell’ambito delle strutture organizzative dell’amministrazione, quali dati, tra tutti quelli prodotti, si vogliano rendere aperti, in quanto riutilizzabili da cittadini, imprese e stakeholder in genere, anche per abilitare nuove forme di riutilizzo dell’informazione. Per i dati mashup, le amministrazioni possono raccogliere e integrare informazioni da diverse fonti interne ed esterne che concorrano alla formazione del dato. Per tale tipologia di dati, la parte più importante è la definizione delle modalità di accesso a partire dalle politiche dei singoli produttori dei dati e le relative modalità di rilascio e aggiornamento dei dati stessi.
Analisi dei vincoli giuridici - Alla fase di ricognizione fa seguito l’analisi giuridica delle fonti del dato, fondamentale per garantire la sostenibilità nel tempo del processo di produzione e pubblicazione dei dati considerando i possibili vincoli che possono impedirne o limitarne (anche temporalmente) l’apertura, evidenziando limitazioni d’uso, finalità di competenza, determinazione dei diritti e dei termini di licenza, nonché base giuridica, finalità del trattamento e, in ogni caso, protezione dei dati personali eventualmente presenti.
Per supportare tale analisi, si riporta di seguito una breve “check list” utile alla verifica di alcuni aspetti giuridici da sottoporre a valutazione.
- Protezione dei dati personali
- Nel processo di apertura di atti, documenti e/o dati è stata attentamente verificata l’assenza di informazioni riguardanti persone fisiche identificate o identificabili anche indirettamente, ai sensi dell’art. 4, n. 1) del GDPR, valutati anche gli ulteriori aspetti di cui ai punti riportati di seguito?
Più nello specifico:- I dati sono liberi da ogni informazione personale che possa identificare in modo diretto l’individuo (nome, cognome, indirizzo, codice fiscale, patente, telefono, email, foto, descrizione fisica, ecc.)?
- I dati sono liberi da ogni informazione indiretta che possa identificare l’individuo (caratteristiche personali che possono identificare facilmente il soggetto)?
- I dati sono liberi da ogni informazione sensibile riconducibile all’individuo?
- I dati sono liberi da ogni informazione relativa al soggetto che, incrociata con dati comunemente reperibili nel web (ad es. google maps, linked data, ecc.), possa facilmente identificare l’individuo?
- I dati sono liberi da ogni riferimento a profughi, protetti di giustizia, vittime di violenze o in ogni caso categorie protette?
- I servizi di ricerca sui dati sono tali da poter filtrare i dati in modo da ottenere un solo record geolocalizzato, che sia facilmente e direttamente riconducibile ad una persona fisica?
- Nel caso in cui è stata verificata la presenza di dati e informazioni personali, riconducibili in maniera diretta o indiretta a persone fisiche identificate o identificabili, si è provveduto a individuare idonee tecniche di anonimizzazione come indicato nel Parere 05/2014 del Gruppo di lavoro Articolo 29 sulle tecniche di anonimizzazione PAR-05-2014?
- In un’eventuale decisione di rendere riutilizzabili dati personali oggetto di un obbligo di pubblicazione online previsto da un idoneo presupposto normativo ai sensi dell’art. 2-ter, commi 1 e 3, del D. Lgs. 196/2003 (ad es. ai sensi del D. Lgs. 33/2013) o di accogliere eventuali richieste di riutilizzo degli stessi da parte di terzi, è stato valutato se, per quali finalità ed entro quali limiti e condizioni siano eventualmente leciti e non incompatibili utilizzi ulteriori dei dati personali resi pubblici (con esclusione dei dati di cui agli artt. 9-10 del GDPR), sulla base del principio di limitazione della finalità?
- È stata effettuata la valutazione d’impatto in materia di protezione dei dati, ai sensi dell’art. 35 del GDPR, al fine di ridurre il rischio di perdere il controllo sulle medesime informazioni o di dover far fronte a richieste di risarcimento del danno da parte degli interessati?
- Nella predetta analisi di impatto sono state effettuate tutte le valutazioni (anche inerenti alla tipologia di licenza) indicate dal Garante per la protezione dei dati personali nei propri provvedimenti4?
- Si è provveduto a coinvolgere il Responsabile per la protezione dei dati personali, la cui nomina è obbligatoria in ogni PA e nei soggetti indicati dall’art. 37 del GDPR?
- Nel processo di apertura di atti, documenti e/o dati è stata attentamente verificata l’assenza di informazioni riguardanti persone fisiche identificate o identificabili anche indirettamente, ai sensi dell’art. 4, n. 1) del GDPR, valutati anche gli ulteriori aspetti di cui ai punti riportati di seguito?
- Proprietà intellettuale della sorgente
- L’ente è proprietario dei dati, anche se non sono stati creati direttamente da suoi dipendenti?
- Sei sicuro di non usare dati per i quali vi è una licenza o un brevetto di terzi?
- Se i dati non sono del tuo ente, hai un accordo o una licenza che ti autorizzi a pubblicarli?
- Licenza di rilascio
- Stai rilasciando i dati di cui possiedi la proprietà accompagnati da una licenza?
- Limiti alla pubblicazione
- Hai verificato che non vi siano impedimenti di legge o contrattuali per la pubblicazione dei dati?
- Hai verificato che i dati e i documenti non siano tra quelli esclusi dall’applicazione del decreto legislativo n. 36/2006?
- Segretezza
- Hai verificato se non vi siano motivi di ordine pubblico o di sicurezza nazionale, motivi legati al segreto d’ufficio o al segreto di stato o al segreto statistico che ti impediscono la pubblicazione dei dati?
- Temporalizzazione
- I dati sono soggetti per legge a restrizioni temporali di pubblicazione?
- Trasparenza
- I dati hanno dei divieti di legge o giurisprudenziali che impediscono la loro indicizzazione da parte di motori di ricerca?
- Fermi restando i limiti e le garanzie per il trattamento dei dati personali, i dati rientrano nella lista dell’allegato A del d.lgs. 33/2013 D-LGS-33-2013?
L’analisi dei vincoli e, quindi, la verifica sulla possibilità di rendere disponibili i dati per il riutilizzo possono essere ulteriormente supportate prendendo in considerazione l’elenco dei documenti esclusi dall’applicazione del Decreto riportato nel par. 1.2. Se il dato o documento rientra tra uno di quelli dell’elenco di cui sopra, è da escludere dai dati da rendere disponibili come dati aperti. In caso contrario, qualora il dato sia ammesso al riutilizzo, il titolare dei dati deve effettuare una valutazione d’impatto sulla protezione dei dati personali, avendo cura di garantire una protezione dei dati by design e by default.
Definizione della priorità e percorso di apertura - La ricognizione dei dati consente di avere contezza del patrimonio informativo, mentre l’analisi dei vincoli consente di fare una prima selezione dei dati che possono essere resi disponibili per il riutilizzo. Per i dati non soggetti a vincoli, è necessario individuare criteri e modalità di apertura anche in base ad una eventuale scala di priorità basata, per esempio, su un approccio di tipo “demand-driven” che tenga conto dell’impatto economico e sociale nonché del livello di interesse e delle necessità degli utilizzatori.
Tra i criteri da considerare per definire la priorità nell’apertura dei dati possono essere considerati:
- la tipologia di dato cui sia attribuito dal Decreto un enorme potenziale economico (dati dinamici, serie di dati di elevato valore e dati della ricerca) per come definita dal Decreto medesimo;
- l’esistenza di richieste pervenute dai riutilizzatori sulla base dell’art. 5 del Decreto e della procedura di cui al par. 5.2;
- l’esistenza di specifiche disposizioni normative che prevedano di rendere disponibili obbligatoriamente, come dati di tipo aperto, talune tipologie di dati (v. i casi presentati all’inizio di questo paragrafo).
Tale attività potrebbe essere sistematizzata attraverso la definizione di un percorso di apertura dei dati da inserire nel Piano Triennale ICT che ciascuna amministrazione, secondo la roadmap definita dalle Linee d’Azione nel Piano triennale nazionale e le modalità operative fornite da AgID, è chiamata a definire anche utilizzando il format PT reso disponibile da AgID stessa (v. box “Risorse utili”). La predisposizione di tale Piano rientra tra i compiti che la Circolare n. 3/2018 del Ministro per la pubblica amministrazione raccomanda di assegnare al RTD.
A tale proposito, si fa presente che le linee d’azione del Piano Triennale nazionale relative al capitolo sui dati includono, tra l’altro:
- l’individuazione dei dataset di tipo dinamico da rendere disponibili in open data in coerenza con quanto previsto dalla Direttiva e la loro documentazione nel catalogo nazionale dei dati aperti;
- la messa a disposizione dei dati territoriali attraverso i servizi di rete di cui a [INSPIRE-DIR];
- la documentazione dei dati di tipo aperto attraverso il catalogo nazionale dei dati aperti (in corrispondenza del risultato atteso relativo all’aumento del numero di dataset di tipo aperto).
I criteri di prioritizzazione indicati innanzi, quindi, troverebbero fondamento anche nelle azioni che gli enti devono implementare per raggiungere gli obiettivi e i risultati attesi prefissati dal Piano Triennale nazionale.
5.1.3 Analisi
Analisi della qualità dei dati - All’analisi giuridica delle fonti segue l’analisi della qualità dei dati. Per la definizione del concetto di qualità dei dati si può ricorrere alla norma ISO/IEC 25012, secondo cui “la qualità dei dati è il grado in cui le caratteristiche dei dati soddisfano esigenze espresse e implicite quando utilizzati in specifiche condizioni”. Nella sezione dedicata alla “qualità dei dati” (v. par. 5.3) si identificano alcune misure e un metodo di valutazione, basati sugli standard ISO di riferimento.
Bonifica - Generalmente, l’analisi della qualità del dato può richiedere una fase di bonifica che si sostanzia in attività di miglioramento di detta qualità che può essere ottenuto eliminando errori e criticità attraverso processi basati sui dati, tramite il confronto con il mondo reale o il confronto incrociato (matching) con altri dataset, oppure adottando azioni di bonifica basate su processi che hanno la caratteristica di analizzare le cause che hanno portato alla scarsa qualità del dato, in modo anche da rivedere gli stessi processi di produzione del dato per garantirne la qualità nel tempo.
Analisi di processo, (re)ingegnerizzazione dei processi organizzativi e produzione dei dati - Ogni dato ha un proprio ciclo di vita, caratterizzato da uno specifico tasso di aggiornamento o manutenzione. Lo Standard UNI CEI ISO/IEC 25024:2016 “Misurazione della qualità del dato” riporta un esempio dell’intero ciclo di vita del dato composto dalle fasi di: progettazione, acquisizione, integrazione con altri dati, elaborazione, memorizzazione, uso, cancellazione.
Risulta quindi necessario analizzare il processo organizzativo che produce e gestisce il dato per fare in modo che la produzione di quel dato sia consolidata e diventi stabile, secondo la frequenza di aggiornamento e le modalità di rilascio adottate.
È preferibile che l’aggiornamento sia operato dal titolare del dato nativo, di prima produzione, possibilmente in maniera coordinata con le altre strutture organizzative dell’ente ovvero degli altri enti competenti per materia e, in generale, altre organizzazioni, anche al fine di evitare duplicazioni.
A tale proposito, a livello territoriale, si deve tenere conto delle funzioni di raccolta ed elaborazione dati che la legge 7 aprile 2014, n. 56, all’art. 1, comma 85, lettera d) riconosce come funzione fondamentale delle Province e delle Città Metropolitane.
5.1.4 Arricchimento
Una volta che i dati siano stati bonificati, possono essere arricchiti attraverso l’integrazione con altri dati e il linking esterno. L’arricchimento è definito dal documento “Data quality guidelines” del Publications Office5 come risultante del collegamento, ai dati esistenti, dei dati da fonti esterne, ed è un processo che, secondo il documento medesimo, include sia la standardizzazione che specifiche attività di arricchimento vero e proprio.
Chiaramente parlando di arricchimento ci si riferisce a dati già esistenti; le azioni indicate, però, potrebbero essere applicate ai dati già al momento della loro formazione, costituendo buone pratiche da seguire in quella fase.
Vocabolari controllati - Come indicato nel documento “Data quality guidelines”, un livello più alto di standardizzazione può essere raggiunto facendo riferimento a vocabolari controllati RDF, quali elenchi di codici, tassonomie, classificazioni o terminologie, definiti nel Piano Triennale ICT 2017-2019 come “un modo comune e condiviso per organizzare codici e nomenclature ricorrenti in maniera standardizzata e normalizzata”. I vocabolari controllati assegnano a ogni concetto un identificatore univoco e persistente (URI) in modo che quel concetto venga referenziato in maniera non ambigua e garantiscono, inoltre, la gestione in modo coerente delle diverse versioni. Possono essere associate, oltre alle etichette, definizioni e descrizioni anche in diverse lingue.
I vocabolari fanno sì che invece di utilizzare nei dati le etichette, queste possano essere referenziate dagli identificatori univoci assegnati, in modo che, se le etichette dovessero cambiare, il riferimento non deve essere adeguato, riducendo l’onere di manutenzione per titolari e fruitori di dati. Considerato, inoltre, che gli URI possono essere dereferenziati (v. par. 7.1.3), l’etichetta può essere risolta in qualsiasi lingua.
In caso di dati di elevato valore (v. par. 4.3), per specifiche categorie tematiche (ovvero osservazione della terra e ambiente, statistica, imprese e proprietà delle imprese, mobilità) il Regolamento (UE) [REG-HVD] indica esplicitamente che i set di dati DEVONO utilizzare, ove possibile, vocabolari controllati e tassonomie documentati pubblicamente e riconosciuti nell’Unione o a livello internazionale.
I vocabolari controllati sono disponibili nel Catalogo Nazionale della semantica dei dati e, per i dati territoriali, nel Sistema di Registri INSPIRE Italia (v. box “Risorse utili”).
Integrazione con altri dati - L’arricchimento dei dati può essere ottenuto, come detto, anche integrando informazioni da sorgenti esterne rendendo in questo modo i dati di origine più significativi e fruibili. Il valore aggiunto è ottenuto, per esempio, producendo i dati mashup già citati in precedenza.
Linking nei LOD - Come detto, il collegamento (linking) dei dati può aumentarne il valore creando nuove relazioni e consentendo così nuovi tipi di analisi.
Nel caso in cui il processo sia finalizzato alla produzione di linked open data, come evidenziato nelle già citate Linee Guida per l’interoperabilità semantica attraverso i Linked Open Data, “il linking è una funzionalità molto importante e di fatto può essere considerata una forma particolare di arricchimento. La particolarità consiste nel fatto che l’arricchimento avviene grazie all’interlinking fra dataset di origine diversa, tipicamente fra amministrazioni o istituzioni diverse, ma anche, al limite, all’interno di una stessa amministrazione”. Tale collegamento è possibile soprattutto attraverso l’uso coerente di identificatori univoci, gli URI, di cui si è parlato prima e che vengono approfonditi ulteriormente nel par. 7.1.3.
I linked open data, oltre agli URI, si basano su diversi standard, tra cui RDF, e spesso usano vocabolari controllati RDF per rappresentare terminologia controllata del dominio applicativo di riferimento. Nell’allegato B sono riportati, nella prima parte, anche i principali standard di riferimento necessari anche ad abilitare i livelli 4 e 5 del modello dei dati di cui all’allegato A. Utilizzando il framework RDF, si può costruire un grafo semantico, noto anche come grafo della conoscenza, che può essere percorso dalle macchine risolvendo, cioè dereferenziando, gli URI HTTP.
Dai dati così disponibili è possibile estrarre automaticamente informazione e derivare, quindi, contenuto informativo aggiuntivo (inferenza) attraverso ragionatori automatici e query SPARQL (v. le Linee Guida indicate nel box “Risorse utili”).
Alcune delle fasi indicate nel percorso di cui alla Figura 5.1 possono essere comuni al processo di produzione dei Linked Open Data. Tale processo è caratterizzato da altre specifiche fasi, non rappresentate nel percorso comune, ma dettagliate nelle Linee Guida citate innanzi a cui si rimanda, come già raccomandato in precedenza.
5.1.5 Modellazione e documentazione
Una fase molto importante nel processo di preparazione dei dati è la definizione di sintassi (cioè struttura) e semantica (cioè contenuto). Questo, oltre a migliorare l’interoperabilità, la qualità e a facilitarne l’elaborazione, aumenta anche il valore dei dati stessi, poiché l’interpretazione errata dei dati diventa meno probabile quando viene fornito il contesto.
Come detto innanzi, questa fase può corrispondere alla prima del processo nel caso in cui il dato ancora non esista e, quindi, si parte dalla definizione di un’ontologia o comunque di un modello dati del dominio, cioè dalla definizione sintattica e semantica dei dati in termini di entità rappresentate, loro attributi e associazioni (cosiddetta fase di modellazione).
Rientra in questa fase anche la documentazione delle modifiche e degli aggiornamenti dei dati oltre alla gestione delle relative versioni e la storicizzazione.
Schemi dei dati – Per facilitare la corretta interpretazione dei dati da parte del fruitore ed evitare qualsiasi ambiguità nella loro comprensione, è necessario condividere anche gli schemi dei dati, eventualmente specificati separatamente, che forniscono la descrizione di sintassi e struttura dei dati stessi.
A titolo di esempio, con riferimento ad alcuni formati riportati al par. 2 dell’Allegato B (CSV, JSON, XML), gli schemi che potrebbero essere utilizzati sono i seguenti:
- JSON Schema per il formato JSON;
- XSD (XML Schema Definition)6 per il formato XML;
- Table Schema per il formato CSV definito nell’ambito del toolkit Frictionless Data.
Il toolkit Frictionless include anche il cosiddetto Data Package, un “formato contenitore” composto dai metadati che descrivono la struttura e il contenuto del pacchetto (memorizzati in un “descrittore”) e le risorse, come i file di dati, che costituiscono il contenuto del pacchetto.
In generale, i metadati di contenuto potrebbero seguire le ontologie nazionali disponibili nel Catalogo nazionale della semantica dei dati, soprattutto per tutti quei dati indipendenti dal dominio specifico.
Modelli dati - Il Piano Triennale ICT 2017-2019 definisce un’ontologia o un modello dati condiviso come “una concettualizzazione esaustiva e rigorosa nell’ambito di un dato dominio”.
Anche per garantire la coerenza tra i documenti, si richiama qui la fase denominata “Semantica” nel processo digitale individuato e descritto nelle Linee Guida per l’interoperabilità tecnica [LG-INT], in cui si evidenzia che la comunicazione tra soggetti DEVE utilizzare modelli dati condivisi, in modo da razionalizzare e uniformare la rappresentazione dell’informazione quale presupposto per favorire l’interoperabilità tra soggetti differenti.
Le Linee Guida di cui sopra hanno già definito una serie di requisiti in tema di modelli dati. Come indicato nel documento citato, pertanto, nell’individuazione delle entità da condividere i diversi soggetti DEVONO:
- individuare i domini di interesse e in essi determinare le entità da rappresentare in termini di proprietà che li caratterizzano;
- verificare la presenza delle entità per dominio tra quelli definiti a livello nazionale nella rete di ontologie e vocabolari pubblicati nel Catalogo Nazionale per la semantica dei dati.
A integrazione di quanto sopra, considerato quanto previsto dall’art. 6, comma 9 del Decreto, i modelli dati da considerare per i dati territoriali sono quelli definiti nell’ambito delle attività di regolamentazione derivanti dalla Direttiva INSPIRE INSPIRE-DIR e nell’ambito del framework nazionale che fa riferimento ai decreti 10/11/2011 e alle attività di estensione delle regole INSPIRE (v. par. 4.5).
Si aggiunge, pertanto, un ulteriore requisito:
- nel caso di dati territoriali, verificare la presenza delle entità per dominio tra quelli definiti a livello europeo e nazionale nell’ambito della regolamentazione INSPIRE e la sua estensione nazionale.
Come indicato nelle citate Linee Guida, successivamente all’attuazione delle regole 2) e 3) ci si può trovare in uno dei seguenti casi:
- tutte le entità e le relative proprietà trovano copertura;
- almeno una delle entità non è compresa nelle rappresentazioni;
- almeno una proprietà di un’entità presente non risulta rappresentata.
Nel caso a), il soggetto ha tutti gli elementi per rappresentare il proprio modello dati; viceversa, nei casi b) e c), la stessa amministrazione, in accordo con AgID, valuta l’opportunità di estendere il modello dati a livello nazionale.
La regola che, in generale, deve guidare, è di esaminare modelli dati, ontologie e vocabolari controllati esistenti per verificare se i concetti siano già provvisti di entità, proprietà e, ove presenti, URI ampiamente adottati, specie se in ambito europeo. Solo in caso contrario, l’ente che pubblica i dati può definire e pubblicare, secondo le regole indicate innanzi, il proprio modello dati, ontologia o vocabolario controllato al fine di definire concetti che non siano stati specificati altrove.
In caso di dati di elevato valore (v. par. 4.3), per tutte le categorie tematiche, tranne quelle relative a dati per i quali si applicano i modelli dati INSPIRE, il Regolamento UE indica esplicitamente che i set di dati DEVONO essere descritti in una documentazione online completa e pubblicamente disponibile che contenga almeno la definizione della struttura e della semantica dei dati.
Conservazione e storicizzazione - I dataset rilasciati costituiscono non solo una risorsa per la collettività, ma un prezioso patrimonio anche per le pubbliche amministrazioni che possono in questo modo archiviare in modo alternativo i loro dati in modalità indipendente dagli applicativi
software originali che li hanno prodotti. Per questo motivo è importante premunirsi di un sistema di archiviazione/conservazione che mantenga le diverse versioni dei dati nel lungo periodo. A tal fine si raccomanda di assicurare che le versioni stesse siano accessibili a un URL stabile, che sia anche documentato unitamente alla pubblicazione del dato.
A tale proposito, il Decreto stabilisce che le pubbliche amministrazioni e gli organismi di diritto pubblico debbano utilizzare le modalità per facilitare la conservazione dei documenti disponibili per il riutilizzo secondo quanto previsto dall’articolo 44 del CAD.
Stante quanto indicato nel par. 4.1 relativamente alla distinzione tra documenti e dati, il REQUISITO 17 si applica solo ai documenti che rientrano nell’ambito di applicazione delle Linee Guida richiamate nel requisito stesso.
5.1.6 Validazione
La validazione dei dati è una parte essenziale di qualsiasi processo di apertura, comunque propedeutica alla pubblicazione e al riutilizzo. Essa viene definita come “un’attività volta a verificare se il valore di un dato proviene dall’insieme dato (finito o infinito) di valori accettabili” o “come un processo che assicura la corrispondenza dei dati finali (pubblicati) con una serie di caratteristiche qualitative”7.
In sintesi, lo scopo della validazione dei dati è quello di assicurare un certo livello di qualità ai dati stessi.
Di analisi di qualità dei dati si è già accennato nella fase post ricognizione dei dati e, come già innanzi, si rimanda al par. 5.3 dedicato alle caratteristiche e alle misure della qualità.
La differenza e le relazioni tra validazione e qualità sono indicate nel documento “Methodology for data validation 2.0” (v. box “Risorse utili”): la validazione dei dati si focalizza sulle dimensioni della qualità relative alla “struttura e al contenuto dei dati”, ma non sugli aspetti della qualità che riguardano i processi. Si può dire, quindi, che la validazione è relativa solo alle caratteristiche di qualità definite “inerenti” nello Standard ISO/IEC 25012:2008 e riportate nel citato par. 5.3.
La fase di validazione può essere un ulteriore passaggio per la verifica dei dati a valle delle altre operazioni effettuate prima della pubblicazione, per es. per l’arricchimento. Può essere anche intesa come la prima e unica fase del processo per la verifica della qualità nel caso di nuovi dati che, quindi, non rientrerebbero nella fase di ricognizione e nella conseguente analisi.
Il documento “Methodology for data validation 2.0” individua sei livelli di validazione che si riportano di seguito rimandando al documento citato per ulteriori approfondimenti.
- Livello 0: coerenza con i requisiti strutturali IT previsti;
- Livello 1: coerenza all’interno del set di dati;
- Livello 2: coerenza con altri set di dati all’interno dello stesso dominio e all’interno della stessa origine dati;
- Livello 3: coerenza all’interno dello stesso dominio tra origini dati diverse;
- Livello 4: coerenza tra domini separati dello stesso fornitore di dati;
- Livello 5: coerenza con i dati di altri fornitori di dati.
5.1.7 Pubblicazione
Prima di procedere alla pubblicazione è necessario creare i metadati, definire le politiche di accesso e il modello di licenza da applicare e identificare i canali per la pubblicazione, anche in base
alla tipologia dei dati, tra accesso diretto (del singolo dataset e/o in blocco), portale dati, API e, in caso di linked open data, triple store.
Nella scelta del canale si devono tenere in considerazione anche i requisiti definiti nelle presenti Linee Guida; ad esempio, per come disposto dal Decreto, i dati dinamici e le serie di dati di elevato valore DEVONO essere resi disponibili attraverso API e, ove possibile, attraverso download in blocco, il che non significa, naturalmente, che non possano essere resi disponibili anche attraverso altri canali ma che quella individuata in prima battuta possa essere l’opzione preferenziale. Il Capitolo 7 fornisce indicazioni, raccomandazioni e ulteriori elementi per la pubblicazione dei dati.
Metadatazione - Come detto precedentemente, la metadatazione è cruciale: i metadati certificano le caratteristiche del dato. Si ricorda, a tale riguardo, di seguire i profili di metadati indicati nel paragrafo 4.6 a cui si rimanda e che consentono di specificare i più importanti metadati descrittivi per i dataset (per es., soggetti e relativi ruoli, contestualizzazione geografica e temporale, licenza, frequenza di aggiornamento, aspetti di distribuzione, punto di contatto, ecc.).
Politiche di accesso e licenza – Nell’ambito del processo di apertura sono da tenere in considerazione eventuali forme di aggregazione dei dati e restrizioni di accesso, che hanno anche un impatto sulla scelta della licenza, della quale si tratterà al Capitolo 6, e sulla protezione dei dati personali. Sebbene sia sconsigliato restringere l’accesso ai dati o procedere con la pubblicazione di aggregazioni degli stessi (in generale non è opportuno che l’esposizione del dato lavorato avvenga senza che sia stato pubblicato prioritariamente il dato grezzo), esistono casi in cui i dati possono essere diffusi solo in forma anonima (ad esempio i redditi), ossia a un livello di aggregazione tale da impedire di identificare le persone cui i dati si riferiscono (cfr. indicazioni in merito presenti nei paragrafi 4.1 e 5.1.2).
A tal fine, è bene definire delle politiche di accesso ai dati in cui sia indicato un profilo di accesso specifico per ogni dato, dettato dai diritti sull’informazione di base, dalle norme o dalle policy in atto, nel rispetto dei principi fondamentali in materia di protezione dei dati personali di cui all’art. 5 del [GDPR].
5.2 Richieste di riutilizzo
L’apertura dei dati può essere un’operazione conseguente anche ad una esplicita richiesta da parte di un soggetto interessato. La Direttiva evidenzia che, in questi casi, i tempi di risposta alle richieste di riutilizzo dei documenti dovrebbero essere ragionevoli ed essere in linea con il tempo necessario per rispondere alle richieste di accesso a un dato documento conformemente ai pertinenti regimi di accesso, come effettivamente recepito con il Decreto, e nel rispetto della normativa unionale e nazionale in materia di protezione dei dati personali (cfr. indicazioni in merito presenti nei paragrafi 4.1 e 5.1.2).
La Direttiva, inoltre, invita gli Stati membri ad incoraggiare, laddove necessario, la creazione di indici accessibili online per i documenti disponibili in modo da promuovere e agevolare le richieste di riutilizzo. Tale raccomandazione può trovare applicazione nell’ordinamento italiano nelle attività di cui all’art. 53, comma 1-bis del CAD volte alla pubblicazione, da parte delle pubbliche amministrazioni, del catalogo dei dati e dei metadati nonché delle relative banche dati in loro possesso, preferibilmente attraverso collegamenti ipertestuali alla sezione del sito in cui sono presenti i relativi dati, le informazioni o i documenti.
Le modalità, i termini e i tempi per le richieste di riutilizzo sono disciplinati dall’art. 5 del Decreto. Sulla base di tali disposizioni e considerato che le pubbliche amministrazioni e gli organismi di diritto pubblico hanno già implementato procedimenti per ottemperare a quanto disposto dall’art. 5 del D. Lgs. n. 33/2013 [D-LGS-33-2013] relativo alle richieste di accesso civico, di seguito viene indicata la procedura da seguire per le richieste di riutilizzo di dati e documenti aperti e il trattamento delle stesse.
La richiesta di riutilizzo PUÒ essere rivolta ad uno degli uffici indicati all’art. 5, comma 3 del D. Lgs. n. 33/2013 [D-LGS-33-2013], ovvero:
- all’ufficio che detiene i dati, le informazioni o i documenti;
- all’Ufficio relazioni con il pubblico;
- ad altro ufficio indicato dall’amministrazione nella sezione “Amministrazione trasparente” del sito istituzionale;
- al responsabile della prevenzione della corruzione e della trasparenza, ove l’istanza abbia ad oggetto dati, informazioni o documenti oggetto di pubblicazione obbligatoria ai sensi del D. Lgs. 33/2013 [D-LGS-33-2013].
Nel caso in cui un’Amministrazione abbia individuato e definito una procedura specifica per la presa in carico e l’espletamento delle richieste di riutilizzo, allora il richiedente DEVE seguire tale procedura by-passando il punto 1. Sulla base del Decreto, sono tenuti a definire specifici termini e modalità di riutilizzo dei dati secondo i rispettivi ordinamenti le imprese pubbliche, gli istituti di istruzione, le organizzazioni che svolgono attività di ricerca, le organizzazioni che finanziano la ricerca, il Dipartimento delle informazioni per la sicurezza (DIS), l’Agenzia informazioni e sicurezza esterna (AISE) e l’Agenzia informazioni e sicurezza interna (AISI).
L’esame delle richieste DEVE essere concluso con la formulazione di una decisione entro 30 giorni. A supporto di tale attività può essere considerato quanto indicato in relazione all’analisi dei vincoli di cui al par. 5.1.2 o in relazione ai “Documenti esclusi dall’applicazione” di cui al par. 1.2
Nel caso le richieste siano numerose o complesse, allora il termine di cui al punto 3. PUÒ essere prorogato di ulteriori 20 giorni previa comunicazione al richiedente entro ventuno giorni dalla richiesta.
Se la decisione è positiva, i documenti oggetto della richiesta DEVONO essere resi disponibili secondo i requisiti definiti nelle presenti Linee Guida.
Se la decisione è negativa, l’ente titolare del dato DEVE motivare il diniego attraverso un apposito provvedimento sulla base delle disposizioni del Decreto (per esempio, se i documenti richiesti rientrano tra i documenti esclusi dall’applicazione del Decreto stesso, v. par. 1.2). Il provvedimento di diniego DEVE includere anche la comunicazione sui mezzi di tutela che il richiedente può esperire sulla base dell’art. 25, commi 4 e 5 della legge 7 agosto 1990, n. 241, mezzi di tutela che per convenienza si riportano al successivo punto 7, fermo restando di fare riferimento in ogni caso ai riferimenti normativi indicati innanzi.
In caso di diniego, il richiedente PUÒ presentare ricorso al tribunale amministrativo regionale, ovvero chiedere, nei confronti degli atti delle amministrazioni comunali, provinciali e regionali, al difensore civico competente per ambito territoriale, ove costituito, o a quello competente per l’ambito territoriale immediatamente superiore, che sia riesaminata la suddetta determinazione. Nei confronti degli atti delle amministrazioni centrali e periferiche dello Stato tale richiesta è inoltrata presso la Commissione per l’accesso ai documenti amministrativi istituita presso la Presidenza del Consiglio dei Ministri nonché presso l’amministrazione resistente. Il difensore civico o la Commissione per l’accesso si pronunciano entro trenta giorni dalla presentazione dell’istanza. Scaduto infruttuosamente tale termine, il ricorso si intende respinto. Se il difensore civico o la Commissione per l’accesso ritengono illegittimo il diniego o il differimento, ne informano il richiedente e lo comunicano all’autorità disponente. Se questa non emana il provvedimento confermativo motivato entro trenta giorni dal ricevimento della comunicazione del difensore civico o della Commissione, l’accesso è consentito e quindi l’ente DEVE seguire le indicazioni di cui al punto 6. Qualora il richiedente l’accesso si sia rivolto al difensore civico o alla Commissione, il termine per ricorrere giudizialmente avverso la decisione del difensore civico o della Commissione decorre dalla data di ricevimento, da parte del richiedente, dell’esito dell’istanza presentata al difensore civico o alla Commissione stessa. Se l’accesso è negato o differito per motivi inerenti ai dati personali che si riferiscono a soggetti terzi, la Commissione provvede, sentito il Garante per la protezione dei dati personali, il quale si pronuncia entro il termine di dieci giorni dalla richiesta, decorso inutilmente il quale il parere si intende reso.
NdR: sul difensore civico per il digitale
AgID ha pubblicato la Guida dei diritti di cittadinanza digitali, di cui l’associazione onData ha creato la versione HTML.
- Nel caso in cui il riutilizzo sia negato perché si tratta di documenti su cui terzi detengono diritti di proprietà intellettuale ai sensi della legge 22 aprile 1941, n. 633, l’ente DEVE indicare la persona fisica o giuridica titolare del diritto, se è nota, oppure il licenziante dal quale il titolare del dato stesso ha ottenuto il materiale. Sono esentati da questa indicazione le biblioteche, comprese quelle universitarie, i musei e gli archivi (cfr. art. 5, comma 4 del Decreto).
5.3 Qualità dei dati
Il miglioramento della qualità dei dati e la maggiore diffusione delle tecniche di misurazione dipendono da vari fattori tra cui l’adesione a modelli di qualità condivisi.
Per determinare la bontà dei dati è necessario definire delle misure attraverso le quali quantificare la qualità dei dati. Lo standard ISO/IEC 25012:2008, divenuto norma italiana UNI CEI ISO/IEC 25012:2014, definisce un insieme di caratteristiche specifiche per la caratterizzazione della qualità dei dati suddivise in “inerenti” (accuratezza, aggiornamento (attualità), completezza, consistenza (coerenza), credibilità), “inerenti e dipendenti dal sistema” (accessibilità, comprensibilità, conformità, efficienza, precisione, riservatezza, tracciabilità) e “dipendenti dal sistema” (disponibilità, portabilità e ripristinabilità).
Sulla base dello standard citato, dal punto di vista inerente, la qualità dei dati si riferisce ai dati stessi, in particolare a: i) valori di dominio dei dati e possibili limitazioni; ii) relazioni di valori di dati; iii) metadati. Riguardo al primo punto, un esempio è rappresentato dalle cosiddette “regole di business” definite in relazione allo specifico contesto operativo per verificare una determinata caratteristica. Tali regole implicano che la qualità dei dati sia parte integrante del processo di produzione del dato in modo da semplificare le operazioni che costituiscono il processo stesso applicando tecniche di qualità dei dati alle informazioni già durante l’elaborazione.
Con riferimento alla qualità dei dati dipendente dal sistema, detta qualità dipende dal dominio tecnologico in cui i dati sono utilizzati.
La qualità dei dati, sebbene riferita a quelli riportati nei siti istituzionali nel rispetto degli obblighi di pubblicazione previsti dalla legge, è anche un obbligo derivante dall’art. 6 del decreto legislativo n. 33/2013 [D-LGS-33-2013] secondo cui si deve assicurare “l’integrità, il costante aggiornamento, la completezza, la tempestività, la semplicità di consultazione, la comprensibilità, l’omogeneità, la facile accessibilità, nonché la conformità ai documenti originali in possesso dell’amministrazione, l’indicazione della loro provenienza e la riutilizzabilità […]”.
Lo stesso art. 6, al comma 2, precisa che “l’esigenza di assicurare adeguata qualità delle informazioni diffuse non può, in ogni caso, costituire motivo per l’omessa o ritardata pubblicazione dei dati, delle informazioni e dei documenti”. Questo implica che sia possibile pubblicare dati e documenti incompleti relativamente alle caratteristiche di qualità indicate per rispettare i tempi di pubblicazione previsti dalle norme. SI RACCOMANDA, però, di indicare i motivi del mancato adempimento derivante dall’art. 6, comma 1 e di procedere successivamente all’aggiornamento dei dati garantendo il rispetto delle caratteristiche di qualità richiamate.
La Determinazione Commissariale n. 68/2013 di AgID, relativa alle regole tecniche per l’identificazione delle basi di dati critiche tra quelle di interesse nazionale specificate sulla base dell’art. 60 del CAD, disponeva che venisse garantito il rispetto di quattro caratteristiche, delle quindici previste dallo Standard ISO/IEC 25012, ovvero:
- accuratezza (sintattica e semantica) - il dato e i suoi attributi rappresentano correttamente il valore reale del concetto o dell’evento a cui ci si riferiscono;
- coerenza - il dato e i suoi attributi non presentano contraddittorietà rispetto ad altri dati del contesto d’uso dell’amministrazione che detiene il dato;
- completezza – il dato risulta esaustivo, sia per tutti i suoi valori attesi e sia rispetto alle entità relative (fonti) che concorrono alla definizione del procedimento a cui si riferisce;
- attualità (o tempestività di aggiornamento) - il dato e i suoi attributi sono del “giusto tempo” (sono aggiornati) rispetto al procedimento a cui si riferiscono.
Altre caratteristiche di qualità sono garantite per via degli adempimenti richiesti da specifiche norme di legge o regole tecniche. Per esempio:
- l’accessibilità è un obbligo derivante dalla legge n.4/2004 e dalle relative Linee Guida AgID;
- la riservatezza è correlata alle indicazioni derivanti dal [GDPR];
- la disponibilità include il disaster recovery;
- la ripristinabilità può essere fornita attraverso meccanismi di backup.
Il passo successivo è quantificare le caratteristiche di qualità in termini di misure, individuando delle soglie che consentano di discriminare la bontà o meno di un dato rispetto alla caratteristica in esame. La fase di valutazione della qualità dei dati è importante in tutti i sistemi informativi indipendentemente dalla scelta/necessità di procedere alla loro apertura. Con l’adozione di politiche di apertura dei dati, la qualità dei dati assume un ruolo ancora più rilevante in quanto elemento per la certificazione della bontà dei dati forniti e soprattutto dell’appropriatezza rispetto all’utilizzo che del dato si vuole fare.
Lo Standard UNI CEI ISO/IEC 25024:2016 “Misurazione della qualità del dato” estende l’UNI CEI ISO/IEC 25012 al campo delle misurazioni, definendo 63 misure di qualità applicabili alle 15 caratteristiche di qualità dei dati, con le relative funzioni di calcolo.
Secondo lo standard, la qualità va ricercata durante l’intero ciclo di vita del dato, un esempio del quale, riportato nello standard stesso, è composto dalle fasi di: progettazione, acquisizione, integrazione con altri dati, elaborazione, memorizzazione, uso, cancellazione.
Nei metadati è possibile indicare qual è il livello di qualità dei dati specificando sia il risultato delle misure applicate che fornendo informazioni relative alle caratteristiche di qualità (per esempio, la frequenza di aggiornamento relativamente all’attualità, l’associazione di una impronta crittografica basata su funzioni di hash relativamente alla integrità dei dati, …).
Nell’elenco che segue si riporta un insieme esemplificativo di misure, sulle 24 definite nello standard ISO per le stesse caratteristiche, a supporto delle attività di valutazione della qualità dei dati delle amministrazioni.
- Completezza, il grado per cui il dato associato a un’entità presenta valori per tutti gli attributi attesi e relative istanze in un certo contesto.
- Si individuano i seguenti livelli di completezza:
- completezza di schema: percentuale di valori nulli per concetti e proprietà rispetto al numero totale di valori attesi;
- completezza dei record: numero di dati elementari associati a un valore non nullo in un record, rispetto al numero di dati elementari del record per cui può essere misurata la completezza;
- completezza di popolazione: percentuale di valori nulli rispetto a una popolazione di riferimento. Si noti che non sempre valori mancanti indicano incompletezza. Per esempio: si supponga di considerare dati relativi ai musei italiani e ai loro canali di contatto (telefono ed email). Può capitare che i musei abbiano tutti un indirizzo email ma non per tutti è presente un numero di telefono.
- Si individuano i seguenti livelli di completezza:
- Accuratezza, Il grado in cui gli attributi rappresentano in maniera corretta il valore reale del dato in uno specifico contesto
- Si individuano due tipi di accuratezza:
- sintattica: ad esempio Merio invece che Mario
- semantica: ad esempio nel caso in cui si utilizzi Marco Rossi intendendo invece un’altra persona per es., Mario Rossi
- Una misura dell’accuratezza è data dal rapporto tra gli attributi dei dati che hanno valori accurati sintatticamente/semanticamente sul numero di attributi dei dati per i quali è richiesta accuratezza sintattica/semantica.
- Si individuano due tipi di accuratezza:
- Coerenza, Il grado in cui gli attributi del dato non sono in contraddizione con altri dati in uno specifico contesto
- Per poter valutare la coerenza una misura è quella che consente di identificare le violazioni di regole semantiche definite su alcuni elementi dei dati.
Per esempio, se una persona è “patentata” non può essere possibile che la sua età sia “17 anni”.
Essa può essere calcolata come il rapporto tra il numero di attributi dei dati i cui valori sono semanticamente corretti nel dataset sul numero di attributi dei dati per i quali sono state definite delle regole semantiche.
Altra misura consiste nel rapporto tra il numero di valori duplicati per ogni attributo della base dati e il numero totale degli elementi della base dati.
- Per poter valutare la coerenza una misura è quella che consente di identificare le violazioni di regole semantiche definite su alcuni elementi dei dati.
- Tempestività, Il grado in cui gli attributi del dato sono al “giusto tempo” rispetto al contesto di riferimento
- La metrica è basata sull’uso dei metadati che indicano quando il dato è stato aggiornato l’ultima volta.
Sulla base di questi metadati, si distinguono poi:- dati con periodicità di aggiornamento nota: in questo caso è possibile calcolare la tempestività in maniera esatta identificando se la data di ultima modifica del dato rispetto al tempo di misurazione ricada nell’intervallo della frequenza di aggiornamento;
- dati con periodicità di aggiornamento media: in questo caso è possibile calcolare la tempestività media con una percentuale di errore.
- La metrica è basata sull’uso dei metadati che indicano quando il dato è stato aggiornato l’ultima volta.
Lo Standard ISO/IEC 25012 è applicabile a tutte le tipologie di dati. Nel caso di dati territoriali, uno standard specifico di riferimento per la qualità è l’ISO 19157 “Geographic information – Data quality”. Alcuni elementi e misure di tale Standard sono utilizzati per
identificare requisiti e raccomandazioni per la qualità dei dati nella sezione “7 - Data quality” delle specifiche sui dati definite per ciascun tema INSPIRE. Per i dati territoriali di cui ai temi INSPIRE, pertanto, dovranno essere considerati gli elementi e le misure definite nelle specifiche citate innanzi, nonché i sistemi di validazione e controllo nazionali ed europei. Per i dati territoriali che fanno riferimento a specifiche diverse, dovranno essere adottati sistemi di verifiche di qualità a cura di soggetti qualificati diversi da quelli che hanno prodotto il dato.
NdR: queste linee guida sono una versione derivata dal documento ufficiale pubblicato da AgID in formato PDF. Questo sito web non è un documento ufficiale e si prega di fare riferimento al suddetto PDF.
- box “Risorse utili” al par. 4.1
- box “Risorse utili” al par. 5.1.4
Open Data Maturity Report (v. https://data.europa.eu/en/publications/open-data-maturity/2022)↩︎
Si veda in particolare: “Linee guida in materia di trattamento di dati personali, contenuti anche in atti e documenti amministrativi, effettuato per finalità di pubblicità e trasparenza sul web da soggetti pubblici e da altri enti obbligati” (provv. n. 243 del 15/5/2014, doc. web n. 3134436) e successivi provvedimenti di aggiornamento.↩︎
- box “Risorse utili” al par. 4.1
- ↩︎
Definizioni riportate nel documento “Methodology for data validation 2.0” (v. https://ec.europa.eu/eurostat/ramon/statmanuals/files/methodology_for_data_validation_v2_0_rev2018.pdf)↩︎